Chapter 5. Pandas 시작하기 (5)
2022. 3. 4. 11:29ㆍ개인활동/파이썬 라이브러리를 활용한 데이터 분석
반응형
기술통계 계산과 요약
> 판다스의 일반적인 수학 메서드 <
- pandas의 메서드는 처음부터 누락된 데이터를 제외하도록 설계
df = pd.DataFrame([[1.4, np.nan], [7.1, -4.5],
[np.nan, np.nan], [0.75, -1.3]],
index=['a', 'b', 'c', 'd'],
columns=['one', 'two'])
df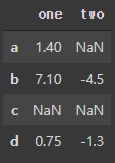
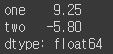
- sum 메서드를 호출하면 각 column의 합을 담은 Series를 반환
df.sum()
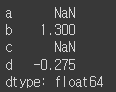
- axis=’columns’ 또는 axis=1 옵션을 넘기면 각 column의 합을 반환
df.sum(axis=1)

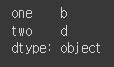
- 전체 low나 column의 값이 NA가 아니라면 NA 값은 제외되고 계산됨
df.mean(axis='columns', skipna=False) # skipna 누락값 제외 안함
[축소 메서드 옵션]
| axis | 연산을 수행할 축. DataFrame에서 0은 low고 1은 column임 |
| skipna | 누락된 값을 제외할 것인지 정하는 옵션. 기본값은 True |
| level | 계산하려는 축이 게층적 색인(다중 색인)이라면 레벨에 따라 묶어서 계산 |
- idxmin이나 idxmax같은 메서드는 최솟값 혹은 최댓값을 가지고 있는 색인값과 같은 간접통계를 반환
df.idxmax()
- 누산(accumulation) 메서드
df.cumsum()

- describe 메서드: 한번에 여러개의 통계 결과를 만들어냄
df.describe()

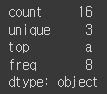
- 수치 데이터가 아닌 경우 describe는 다른 요약통계를 생성함
obj = pd.Series(['a', 'a', 'b', 'c'] * 4)
obj.describe()
[요약통계 관련 메서드]
| count | NA값을 제외한 값의 수를 반환 |
| describe | Series나 DataFrame의 각 column에 대한 요약 통계를 계산 |
| min, max | 최솟값과 최댓값을 계산 |
| argmin, argmax | 각각 최솟값과 최댓값을 담고 있는 색인의 위치를 반환 |
| idxmin, idxmax | 각각 최솟값과 최댓값을 담고 있는 색인의 값을 반환 |
| quantile | 0부터 1까지의 분위수 계산 |
| sum | 합을 계산 |
| mean | 평균을 계산 |
| median | 중간값(50%분위)를 반환 |
| mad | 평균값에서 평균절대편차를 계산 |
| prod | 모든값의 곱 |
| var | 표본분산의 값을 계산 |
| std | 표본표준편차의 값 계산 |
| skew | 표본 비대칭도(3차 적률)의 값을 계산 |
| kurt | 표본첨도(4차 적률)의 값을 계산 |
| cumsum | 누적합을 계산 |
| cummin, cummax | 각각 누적 최솟값과 누적 최댓값을 계싼 |
| cumprod | 누적 곱을 계산 |
| diff | 1차 산술차를 계산(시계열 데이터 처리 시 유용) |
| pct_change | 퍼센트 변화율 계산 |
> 상관관계와 공분산 <
- 상관관계나 공분산과 같은 요약통계 계산은 두쌍의 argument를 필요로 함
- pandas-datareader 패키지를 이용한 상관관계와 공분산 계산
- 책에 나와있는 예제의 경우 현재 서비스가 더이상 작동하지 않아 메서드 설명만 간단히 하려고 함
- corr 메서드: na값이 아닌 정렬된 index에서 연속하는 두 Series에 대해 상관관계를 계산
- 공분산: 두개의 연속형 변수의 관계성을 확인하는 통계량
- cov 메서드: na값이 아닌 정렬된 index에서 연속하는 두 Series에 대해 공분산을 계산
공분산>0 변수 한쪽이 큰 값을 갖게되면 다른 한쪽도 커지는 관계 공분산=0 변수사이의 관계성이 없음 공분산<0 변수 한쪽이 커지면 다른 한쪽은 작아짐
- corrwith 메서드: 다른 Series나 DataFrame과의 상관관계를 계산
- axis=’columns’ : 각 column에 대한 상관관계와 공분산을 계산할 수 있는 옵션
> 유일값, 값세기, 멤버십 <
- unique 메서드: 중복되는 값을 제거하고 유일값만 담고있는 Series를 반환
obj = pd.Series(['c', 'a', 'd', 'a', 'a', 'b', 'b', 'c', 'c'])
uniques = obj.unique()
uniques

- 정렬된 순서로 반환하지 않음
uniques.sort() # 정렬
- obj = pd.Series(['c', 'a', 'd', 'a', 'a', 'b', 'b', 'c', 'c'])
values_counts 메서드: Series에서 도수(frequency)를 계산하여 반환
- pandas 최상위 메서드로 어떤 배열이나 순차 자료구조에서도 사용할 수 있음
- 반환하는 Series는 담고있는 값을 내림차순으로 정렬
pd.value_counts(obj.values)
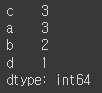
pd.value_counts(obj.values, sort=False) # 정렬X
- isin 메서드: 어떤 값이 Series에 존재하는지 나타내는 boolean 벡터를 반환
- Series나 Data Frame의 column에서 값을 골라낼 때 유용하게 사용할 수 있음
obj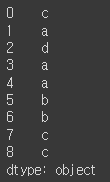
mask = obj.isin(['b', 'c'])
mask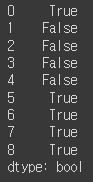
obj[mask]
- Index.get_indexer 메서드: 여러 값이 들어있는 배열에서 유일한 값의 index 배열을 구할 수 있음
to_match = pd.Series(['c', 'a', 'b', 'b', 'c', 'a'])
unique_vals = pd.Series(['c', 'b', 'a'])
pd.Index(unique_vals).get_indexer(to_match)

- Data Frame의 여러 column에 대해 히스토그램을 구해야 하는 경우
data = pd.DataFrame({'Qu1' : [1, 3, 4, 3, 4],
'Qu2' : [2, 3, 1, 2, 3],
'Qu3' : [1, 5, 2, 4, 4]})
data
result = data.apply(pd.value_counts).fillna(0)
result
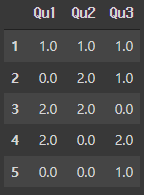
- 1~5의 값이 각각 몇번 나왔는지를 나타냄
- NA 값은 0으로 채움
| isin | Series의 각 원소가 넘겨받은 연속된값에 속하는지 나타내는 불리언 배열을 반환 |
| match | 각 값에 대해 유일한 값을 담고 있는 배열에서의 정수 색인을 계산함. 데이터 정렬이나 조인 형태의 연산을 하는 경우에 유용 |
| unique | Series에서 중복되는 값을 제거하고 유일값만 포함하는 배열을 반환. 결과는 Series에서 발견된 순서대로 반환 |
| value_counts | Series에서 유일값에 대한 색인과 도수를 계싼. 도수는 내림차순으로 정렬 |
반응형
'개인활동 > 파이썬 라이브러리를 활용한 데이터 분석' 카테고리의 다른 글
| Chapter 8. 데이터 준비하기: 조인, 병합, 변형 (1) (0) | 2022.03.14 |
|---|---|
| Chapter 5. Pandas 시작하기 (4) (0) | 2022.03.03 |
| Chapter 5. Pandas 시작하기 (3) (0) | 2022.03.03 |
| Chapter 5. Pandas 시작하기 (2) (0) | 2022.03.01 |
| Chapter 5. Pandas 시작하기 (1) (0) | 2022.03.01 |