Chapter 5. Pandas 시작하기 (4)
2022. 3. 3. 14:48ㆍ개인활동/파이썬 라이브러리를 활용한 데이터 분석
반응형
핵심 기능
> 정렬과 순위 <
- low나 column의 index를 알파벳 순으로 정렬하기
obj = pd.Series(range(4), index=['d', 'a', 'b', 'c'])
obj.sort_index() # 정렬된 새로운 객체를 반환

frame = pd.DataFrame(np.arnage(8).reshape((2, 4)),
index=['three', 'one'],
columns=['d', 'a', 'b', 'c'])
frame.sort_index()
frame.sort_index(axis=1) #col을 기준으로 정렬


- 데이터는 기본적으로 오름차순으로 정렬되며 내림차순으로도 정렬 가능
frame.sort_index(axis=1, ascending=False) #col을 기준으로 정렬, 오름차순=false

- Series 객체를 값에 따라 정렬할 때
- 정렬할 때 비어있는 값은 Series 객체에서 가장 마지막에 위치함
obj = pd.Series([4, 7, -3, 2])
obj.sort_values()

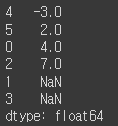
obj = pd.Series([4, np.nan, 7, np.nan, -3, 2])
obj.sort_values
- DataFrame에서 하나 이상의 column에 있는 값으로 정렬하는 경우 sort_values 함수의 by 옵션에 하나 이상의 column 명을 남기면 됨
frame = pd.DataFrame({'b' : [4, 7, -3, 2], 'a' : [0, 1, 0, 1]})
frame

frame.sort_values(by='b')

- 여러개의 column을 정렬하려면 column 이름이 담긴 리스트를 전달하면 됨
frame.sort_values(by=['a', 'b'])

- 순위: 1부터 배열의 유효한 데이터 개수까지 순서를 매김
- rank 메서드: 동점인 항목에 대해서는 평균 순위를 매김
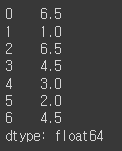
obj = pd.Series([7, -5, 7, 4, 2, 0, 4])
obj.rank()
- 데이터 상에서 나타나는 순서에 따라 순위를 매길 수 있음
obj.rank(method='first') # 동점 항목에 대해서 먼저 나타난 것을 먼저 순위로 매김

- 내림차순으로 순위 매기기
obj.rank(ascending=False, method='max') # 동점처리함

- DataFrame에서는 low나 col에 대해 순위를 정할 수 있음
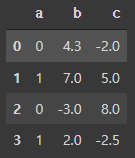
frame = pd.DataFrame({'b' : [4.3, 7, -3, 2], 'a' : [0, 1, 0, 1],
'c' : [-2, 5, 8, 2.5]})
frame
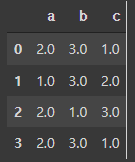
frame.rank(axis='columns')
| ‘average’ | 기본값. 같은 값을 가지는 항목들의 평균 값을 순위로 삼음 |
| ‘min' | 같은 값을 가지는 그룹을 낮은 순위로 매김 |
| ‘max’ | 같은 값을 가지는 그룹을 높은 순위로 매김 |
| ‘first’ | 데이터 내의 위치에 따라 순위를 매김 |
| ‘dense | method=’min’과 같지만 같은 그룹 내에서 모두 같은 순위를 적용하지 않고 1씩 증가시킴 |
> 중복 index <
- 중복된 색인값을 가지는 Series 객체
obj = pd.Series(range(5), index=['a', 'a', 'b', 'b', 'c'])
obj

obj.index.is_unique # 해당값이 유일값인지 알려줌
#False
- 중복되는 index값이 있는 경우 index 값을 이용해 데이터에 접근했을 때 다르게 동작함
- 중복되는 색인값이 없을 때: 색인을 이용해 데이터에 접근하면 스칼라값을 반환
- 중복되는 색인값이 있을 때: 하나의 Series 객체를 반환
obj['a']
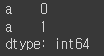
obj['c']

- 라벨이 반복되는지의 여부에 따라 색인을 이용해 선택한 결과가 다를 수 있음
df = pd.DataFrame(np.random.randn(4, 3), index=['a', 'a', 'b', 'b'])
df

df.loc['b']

반응형
'개인활동 > 파이썬 라이브러리를 활용한 데이터 분석' 카테고리의 다른 글
| Chapter 8. 데이터 준비하기: 조인, 병합, 변형 (1) (0) | 2022.03.14 |
|---|---|
| Chapter 5. Pandas 시작하기 (5) (0) | 2022.03.04 |
| Chapter 5. Pandas 시작하기 (3) (0) | 2022.03.03 |
| Chapter 5. Pandas 시작하기 (2) (0) | 2022.03.01 |
| Chapter 5. Pandas 시작하기 (1) (0) | 2022.03.01 |