Chapter 5. Pandas 시작하기 (1)
2022. 3. 1. 21:00ㆍ개인활동/파이썬 라이브러리를 활용한 데이터 분석
반응형
Pandas의 특징
- numpy, scikit-learn, matplotlib 등의 다른 라이브러리와 함께 사용함
- for문을 사용하지 않고 데이터를 처리함
- 배열기반의 함수를 제공
- numpy의 스타일을 많이 차용했으나 표 형식의 데이터나 다양한 형태의 데이터를 다루는데 초점을 맞추어 설계
Pandas import하기
import pandas as pd
- pandas를 pd로 지칭하여 편하게 불러올 수 있도록 함
Pandas 자료구조
> Series <
- 1차원 배열의 자료구조
- index는 배열의 데이터와 연관된 이름을 가짐
obj1 = pd.Series([4, 7, -5, 3])
obj1
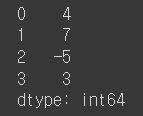
- 좌측의 0, 1, 2, 3은 index, 우측의 데이터 값을 value라고 함
- index를 따로 지정해주지 않는 경우 0~(n-1)의 값을 가짐
- Series의 index값과 value값을 얻어낼 수 있는 속성은 각각 index와 values가 있음
obj1.index # 인덱스를 따로 지정하지 않은 경우: 인덱스의 시작점과 끝점, 그리고 인덱스 사이의 간격을 알 수 있음
obj1.values # values에서 s를 빼먹지 않도록 조심하자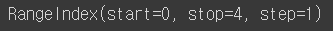

- Series의 index값을 지정해준 경우
obj2 = pd.Series([4, 7, -5, 3], index=['a', 'b', 'c', 'd'])
obj2

- Series의 index값을 지정해준 경우 index 속성을 이용하면?
obj2.index
- Series의 하나의 값을 선택하거나 여러개의 값을 선택할 때 index를 이용해 출력할 수 있음
obj2['a']

obj2[['a', 'b']] # index를 여러개 적는 경우, 두겹의 리스트로 작성해 주어야 함. index 또한 배열로 해석되기 때문.

- 두겹의 리스트로 작성하지 않으면?
obj2['a', 'b']
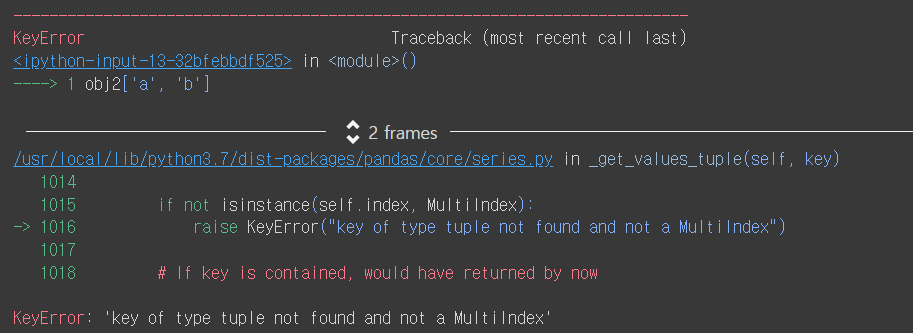
- index가 a인 value 값을 출력할 때 obj2[[’a’]]를 이용하면 어떤 결과값이 나올까?
obj2[['a']]
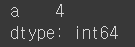
- Series는 index값에 특정 데이터 값을 가지고 있는 형태 → 이는 딕셔너리 자료형과 유사한 형태라고 볼 수 있음
- 딕셔너리형 데이터를 Series로 변환하기
sdata = {'Ohio':35000, 'Texas':71000, 'Oregon':16000, 'Utah':5000}
obj3 = pd.Series(sdata)
obj3

states = ['California', 'Ohio', 'Oregon', 'Texas']
obj4 = pd.Series(sdata, index=states)
obj4
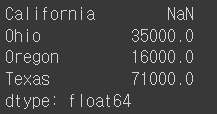
- sdata의 index와 states index를 비교했을 때 겹치는 부분은 값이 나오지만 California의 경우 값이 존재하지 않아 NaN(Not a Number)으로 나타남
- obj4의 경우 index는 states로 지정했기 때문에 sdata의 인덱스는 기준이 아님 → Utah는 나타나지 않음
- NA값을 찾는 방법: isnull() 또는 notnull() 함수를 이용해 NA값을 찾을 수 있음 (bool 값으로 반환)
pd.isnull(obj4) # == obj4.isnull()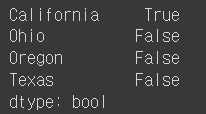
pd.notnull(obj4) # == obj4.notnull()
- isnull(), notnull() 함수는 Series의 메서드로도 존재해 위와같은 코드처럼 사용할 수 있음
- obj3과 obj4의 산술 연산이 가능할까?
obj3 + obj4
- Series의 객체와 index는 name 속성을 가지고 있음 → Series 객체 자체에 이름을 붙일 수 있으며, index에도 이름을 붙일 수 있음
obj4.name = 'population'
obj4.index.name = 'state'
obj4
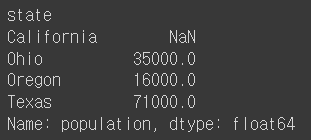
- 기존의 index에 다른 index 이름을 대입할 수 있음
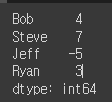
obj1

obj1.index = ['Bob', 'Steve', 'Jeff', 'Ryan']
obj1
> Data Frame <
- DataFrame은 표같은 스프레드시트 형식의 자료구조
- 여러개의 column이 있을 수 있으며, 서로 다른 data type을 담을 수 있음
- low, col 각각 index를 가지고 있음
- DF 객체 생성하기
- 딕셔너리형 이용하기
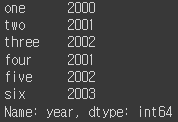
data = {'state' : ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'], 'year' : [2000, 2001, 2002, 2001, 2002, 2003], 'pop' : [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]} frame = pd.DataFrame(data) frame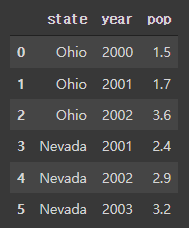
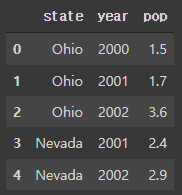
- 큰 DataFrame을 다루는 경우 head 메서드를 이용해 처음 5개의 로우만 출력할 수 있음
frame.head()
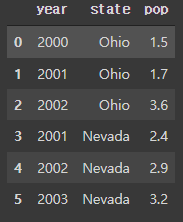
- 원하는 순서대로 column을 지정해주면 그 순서대로 DF 객체가 생성됨
pd.DataFrame(data, columns=['year', 'state', 'pop'])
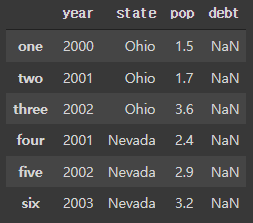
- 사전에 없는 값을 넘기면 Na값으로 저장
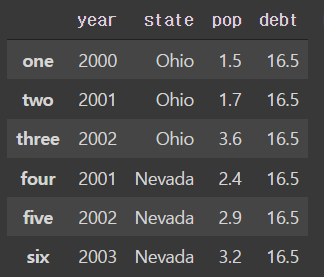
frame2 = pd.DataFrame(data, columns=['year', 'state', 'pop', 'debt'],
index=['one', 'two', 'three', 'four', 'five', 'six'])
frame2
- column은 딕셔너리형 표기법이나 속성 형식으로 접근할 수 있음
frame2['state']
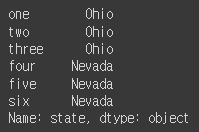
frame2.year
- 속성 형식으로 접근할 때 column명이 예약어인 경우 속성형식으로 접근 불가
- low는 위치나 loc 속성을 이용해 index 이름으로 접근할 수 있음
frame2.loc['three']
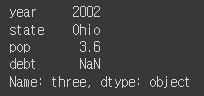
frame2.loc[2]

- index의 이름이 2가 아니기 때문에 오류남.
- 새로운 column 생성하기
frame2['debt'] = 16.5
frame2
- 리스트나 배열을 column에 대입할 때 대입하려는 값의 길이가 DataFrame의 크기와 동일해야함
frame2['debt'] = np.arange(6.) # numpy의 arange 함수: 0부터 4.0까지 대입
frame2
- DataFrame에 Series 데이터를 대입하는 경우 index 값에 따라 대입되며, 존재하지 않는 index의 값은 Na처리됨
val = pd.Series([-1.2, -1.5, -1.7], index=['two', 'four', 'five'])
frame2['debt'] = val
frame2

- 존재하지 않는 column을 대입하는 경우 새로운 column을 생성함
- 딕셔너리처럼 del을 이용해 column 삭제 가능
frame2['eastern'] = frame2.state == 'Ohio' # state에서 Ohio를 포함하고 있는지를 bool 값으로 반환해주는 col
frame2
del frame2['eastern']
frame2.columns #frame2를 구성하고 있는 col을 볼 수 있음

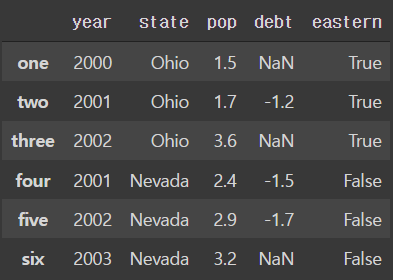
- 중첩된 딕셔너리형 데이터를 이용한 DF 생성
pop = {'Nevada' : {2001:2.4, 2002:2.9},
'Ohio' : {2000:1.5, 2001:1.7, 2002:3.6}}
frame3 = pd.DataFrame(pop)
frame3
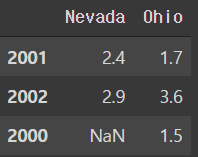
- 데이터 전치
frame3.T
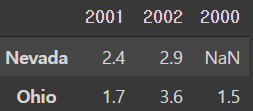
- 중첩된 dic을 이용해 DF을 생성할 때, 안쪽의 dictionary의 key값을 중심으로 조합을 해서 index를 만드는데 이때 index를 직접 지정하는 경우 지정된 index로 DF를 생성
pd.DataFrame(pop, index=[2001, 2002, 2003])
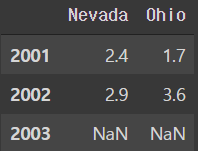
pdata = {'Ohio' : frame3['Ohio'][:-1],
'Nevada' : frame3['Nevada'][:2]}
pd.DataFrame(pdata)

- index와 columns에 name 속성을 지정하는 경우 이와 함께 출력
frame3.index.name = 'year' ; frame3.columns.name = 'state'
frame3
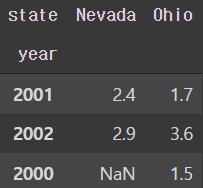
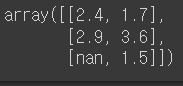
- values 속성은 DF에 저장된 데이터를 2차원 array로 반환
frame3.values
- column들이 서로 다른 dtype을 가지고 있는 경우, 모든 col을 수용하기 위해 그 column의 dtype을 선택
frame2.values

- 다른 타입들을 모두 수용하기 위해 dtype=object로 선택됨
색인객체
- 표 형식의 데이터에서 각 low와 col에 대한 이름과 다른 메타데이터(축의 이름 등)을 저장하는 객체
- Series나 Data Frame 객체를 생성할 때 사용되는 배열이나 다른 순차적인 이름은 내부적으로 index로 변환됨
obj = pd.Series(range(3), index=['a', 'b', 'c'])
index = obj.index
index # <- 색인 객체
- 색인객체는 변경이 불가함
index[1] = 'd'
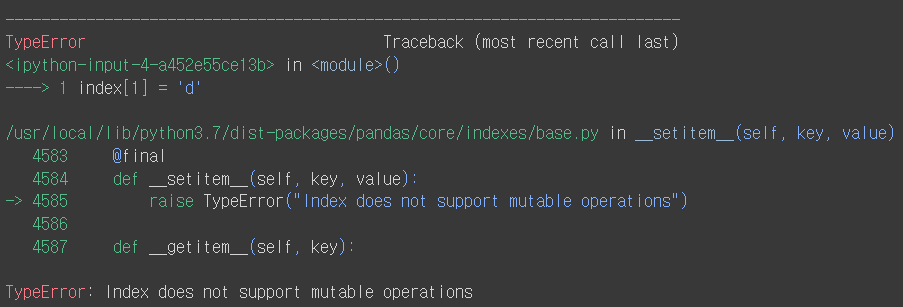
- index는 mutable한 동작을 지원하지 않는다는 오류 발생
- 색인 객체의 변경이 불가능하기 때문에 자료구조 사이에서 안전하게 공유될 수 있음
labels = pd.Index(np.arange(3))
# labels에는 0~2까지의 index 객체를 할당
obj2 = pd.Series([1.5, -2.5, 0] ,index=labels)
# obj2에는 Series 객체가 할당되었으며, 이 객체의 index는 labels에 저장된 index 객체를 이용함
obj2.index is labels
# True 반환
- pandas의 index는 중복되는 값을 허용함
dup_lables = pd.Index(['foo', 'foo', 'bar', 'bar'])
dup_lables

- 하지만 중복되는 index를 선택하는 경우 해당 값을 가진 모든 index가 선택됨
- 각각의 index는 자신이 담고 있는 데이터에 대한 정보를 취급하기 위해 여러가지 메서드와 속성을 가지고 있음
append 추가적인 index 객체를 덧붙여 새로운 index를 반환
| difference | index의 차집합을 반환 |
| intersection | index의 교집합을 반환 |
| union | index의 합집합을 반환 |
| isin | index가 넘겨받은 index 목록에 존재하는지 알려주는 boolean 배열 반환 |
| delete | i 위치의 index가 삭제된 새로운 index를 반환 |
| drop | 넘겨받은 값이 삭제된 새로운 index를 반환 |
| insert | i 위치에 index가 추가된 새로운 index를 반환 |
| is_monotonic | index가 단조성(주어진 순서를 보존하는 성질?)을 가진다면 참을 반환 |
| is_unique | 중복되는 index가 없다면 참을 반환 |
| unique | 중복되는 index 요소를 제거하고 유일한 값만 반환 |
반응형
'개인활동 > 파이썬 라이브러리를 활용한 데이터 분석' 카테고리의 다른 글
| Chapter 8. 데이터 준비하기: 조인, 병합, 변형 (1) (0) | 2022.03.14 |
|---|---|
| Chapter 5. Pandas 시작하기 (5) (0) | 2022.03.04 |
| Chapter 5. Pandas 시작하기 (4) (0) | 2022.03.03 |
| Chapter 5. Pandas 시작하기 (3) (0) | 2022.03.03 |
| Chapter 5. Pandas 시작하기 (2) (0) | 2022.03.01 |