Chapter 5. Pandas 시작하기 (3)
2022. 3. 3. 13:49ㆍ개인활동/파이썬 라이브러리를 활용한 데이터 분석
반응형
핵심 기능
> 정수 index <
- 판다스는 일관성을 유지하기 위해 정숫값을 담고 있는 축 index가 있다면 우선적으로 라벨을 먼저 찾아보도록 구현되어있음
- 라벨에 대해서는 loc 인덱서를, 정수 index에 대해서는 iloc인덱서를 사용
ser = pd.Series(np.arange(3.))
ser.loc[:1]
ser.iloc[:1]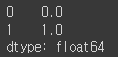

> 산술연산과 데이터 정렬 <
- 다른 색인을 가지고 있는 객체간의 산술 연산의 경우 짝이 맞지 않는다면 결과에 두 색인이 통합됨
- 서로겹치는 색인이 없는 경우 데이터는 NA
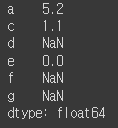
s1 = pd.Series([7.3, -2.5, 3.4, 1.5], index=['a', 'c', 'd', 'e'])
s2 = pd.Series([-2.1, 3.6, -1.5, 4, 3.1], index=['a', 'c', 'e', 'f', 'g'])
s1+s2
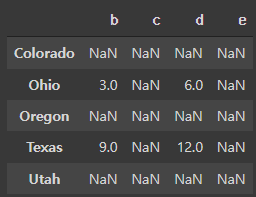
df1 = pd.DataFrame(np.arange(9.0).reshape((3, 3)), columns=list('bcd'),
index=['Ohio', 'Texas', 'Colorado'])
df2 = pd.DataFrame(np.arange(12.).reshape((4, 3)), columns=list('bde'),
index=['Utah', 'Ohio', 'Texas', 'Oregon'])
df1+df2
df1 = pd.DataFrame({'A' : [1, 2]})
df2 = pd.DataFrame({'B' : [3, 4]})
df1-df2

- 존재하지 않는 축의 값을 특수한 값으로 지정하려는 경우
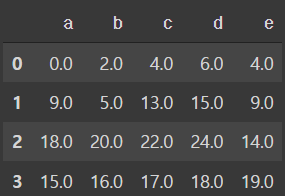
df1 = pd.DataFrame(np.arange(12.).reshape((3, 4)),
columns=list('abcd'))
df2 = pd.DataFrame(np.arange(20.).reshape((4, 5)),
columns=list('abcde'))
df2.loc[1, 'b'] = np.nan
df1+df2

# add method 이용하여 na값 채우기
df1.add(df2, fill_value=0)
- DF - Series
- 각 low에 대해 한번씩 계산을 수행 = 브로드캐스팅
arr = np.arange(12.).reshape(3, 4)
arr - arr[0]

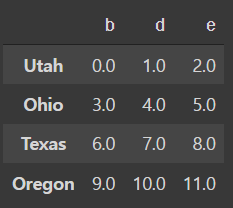
frame = pd.DataFrame(np.arange(12.).reshape((4, 3)),
columns=list('bde'),
index=['Utah', 'Ohio', 'Texas', 'Oregon'])
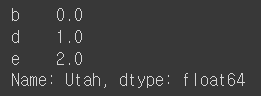
series = frame.iloc[0]
frame
series
frame-series

- Series의 색인을 DF의 col에 맞춰 아래 low로 전파
- 연산 메소드의 파라미터인 axis의 값을 ‘index’나 0으로 설정하는 경우 DF의 low를 따라 연산하라는 의미
- index값을 Data Frame의 column이나 Series의 색인에서 찾을 수 없다면 그 객체는 형식을 맞추기 위해 재색인 됨
series2 = pd.Series(range(3), index=['b', 'e', 'f'])
frame+series2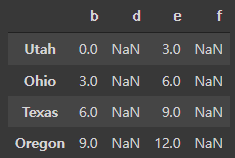
> 함수 적용과 매핑 <
- pandas 객체에도 numpy의 유니버설 함수(배열의 각 원소에 적용되는 메서드)를 적용할 수 있음
frame = pd.DataFrame(np.random.randn(4, 3), columns=list('bde'),
index=['Utah', 'Ohio', 'Texas', 'Oregon'])
frame
np.abs(frame) # 절댓값 메서드

- 각 column이나 low의 1차원 배열에 함수를 적용하는 연산
f = lambda x : x.max() - x.min()
frame.apply(f)

- 함수 f는 Series의 최댓값과 최솟값의 차이를 계산하는 함수로 각 column에 대해 한번만 수행되며 결괏값은 계산을 적용한 column을 index로 가지는 Series를 반환
- apply 메서드는 행이나 열에 대해 함수를 적용할 수 있도록 해주는 메서드
- apply 함수에 axis=’columns’ 아규먼트를 넘기면 각 로우에 대해 한번씩 수행
frame.apply(f, axis='columns')

- 배열에 대한 일반적인 통계 메서드(sum이나 mean같은)는 Data Frame의 메서드로 존재하기 때문에 apply 메서드를 이용할 필요가 없음
- apply 메서드에 전달된 함수는 스칼라 값을 반환 할 필요가 없음
- 여러 값을 가진 series를 반환해도 됨
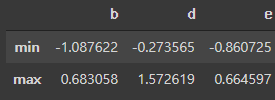
def f(x):
return pd.Series([x.min(), x.max()], index=['min', 'max'])
frame.apply(f)
- 배열의 각 원소에 적용되는 메서드 사용 가능
- applymap 메서드를 이용해 frame 객체에서 실숫값을 문자열 포맷으로 변환하기
format = lambda x : '%.2f' %x frame.applymap(format)
- Series는 각 원소에 적용할 함수를 지정하기 위한 map 메서드를 가짐
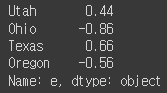
frame['e'].map(format)
반응형
'개인활동 > 파이썬 라이브러리를 활용한 데이터 분석' 카테고리의 다른 글
| Chapter 8. 데이터 준비하기: 조인, 병합, 변형 (1) (0) | 2022.03.14 |
|---|---|
| Chapter 5. Pandas 시작하기 (5) (0) | 2022.03.04 |
| Chapter 5. Pandas 시작하기 (4) (0) | 2022.03.03 |
| Chapter 5. Pandas 시작하기 (2) (0) | 2022.03.01 |
| Chapter 5. Pandas 시작하기 (1) (0) | 2022.03.01 |