2023. 2. 2. 21:31ㆍ2022/데이터시각화
본 기말 프로젝트는 데이터시각화 수업 중 진행된 팀프로젝트를 전반적인 과정을 다룬 글입니다.
1. 주제 선정 이유
이태원 참사를 계기로 출퇴근 시간대 안전사고에 대한 우려가 높아진 가운데 "압사" 키워드 검색량이 증가한 것으로 보아 압사사고에 대한 경각심 또한 증가한 것으로 보인다. 이를 바탕으로 지하철 승하차인원과 혼잡도 데이터 분석을 통해 지역별 지하철 및 전철역의 시간대별 인구 밀집도를 제공하고, 지하철 이용객의 경우 역대 시간대별 밀집도를 확인하여 승객이 붐비는 시간대에 사고의 위험성을 줄이고자 한다.
2. 문제 정의
우리는 특정 역의 특정 시간대에 사람이 얼마나 붐비는지 알기 어려우며, "또타 지하철"에서 티맵과 연계하여 열차 내 혼잡도를 제공하고 있으나, 열차 내부가 아닌 역사의 플랫폼에서의 혼잡도는 제공하지 않고 있다. 특히 출퇴근 시간에 열차 탑승 전 승차자와 하차자가 뒤섞이며 발생하는 압력으로 인한 불안감도 상승하였다.
이런 문제들을 보여주는 시각화 자료는 다음과 같다.

첫번째 그래프는 네이버 데이터랩의 키워드 데이터를 통한 압사 키워드 검색량 추이를 보여준다. 이 그래프를 통해 이태원 참사 발생일인 2022년 10월 29일을 기준으로 압사 검색량이 급증했음을 알 수 있다.
두번째 그래프는 승하차 데이터를 이용해 승하차 인원 상위 3개의 역을 뽑은 것으로, 이를 통해 잠실역, 서울역, 홍대입구역이 가장 유동인구가 많은 것을 알 수 있다.
마지막 그래프는 두번째 그래프의 상위 3개 역인 잠실, 서울, 홍대입구역의 혼잡도를 보여준다. 세 역 모두 오전 8시 30분, 오후 6시가 가장 혼잡도가 높음을 알 수 있다.
이 그래프들을 통해 역사 플랫폼 내의 혼잡도의 제공 또한 의미있고 중요하다는 점을 파악할 수 있으며, 우리는 태블로를 이용해 각 시간대별 역사 플랫폼 내의 혼잡도를 제공하고자 했다.
3. 이용 데이터
1) 지하철 노선도 역 위치 좌표
2) 지하철 승하차 데이터
3) 네이버 데이터랩 키워드 데이터
4) 지하철 혼잡도 데이터
3, 4번의 경우에는 바로 위의 문제정의 부분에서 시각화할 때 사용한 데이터들이다.
본 프로젝트에서 주로 사용한 데이터는 1, 2번 데이터이며 아쉬운 점이 좀 많았다.
아쉬운 점을 먼저 이야기하자면
i) 지하철 위경도 좌표 시각화 실패
왜인지 모르겠으나, 지하철 위경도 좌표가 촥 뿌려지지 않았다. 이산형으로 변환 후 뿌렸음에도 불구하고 지도위에 뿌려지지 않았으며, 데이터 시각화 전 데이터타입도 위경도로 변환했으나 뿌려지지 않았다. 이게뭘까?
ii) 태블로의 편리한 기능을 충분히 이용하지 못함
데이터 피벗을 이용하면.. 노가다를 하지 않아도 됐었는데... 왜 우린 수작업을 하고 있었을까?
왜 이생각을 못했을까?
왜 우린 엑셀로 노가다를 하고 있었던 것인가?
왜 나를 말리지 않았는가 ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
....
여튼 다시 생각해보면 태블로로 쉽게 전처리할 수 있던 것들을 .. 우리는 노가다로 한 것 같다.
iii) 완벽하지 못했던 EDA(?)
역사 데이터와 승하차 데이터.. 역사 데이터를 봤을 때 이상함을 느껴야 했는데...
1호선이 정말 많이 쪼개져 있었다.
경부선, 경인선, ... 기타등등
3호선도 쪼개져 있었다. 3호선, 일산선...
7호선도 쪼개져 있었다. 7호선, 7호선(인천) (이였나..?)
이렇게 쪼개져있던 이유는... 서울 넘어가면 관할이 바뀌는 경우가 있어서 그런가보다..
iv) 좀 더 복합적인 시각화
또 아쉬웠던 점은 환승 인원을 제대로 고려하지 못했다는 점도 있었다. 물론 승하차 인원에 환승인원도 포함이 되어있겠지만 환승통로의 면적과 환승인원도 고려할 수 있었다면 더 좋은 결과물을 얻을 수 있었을 것 같다.
승하차데이터는 서울시 지하철 승하차데이터였고, 인천쪽, 안산과천, 일산, 의정부 등 서울을 제외한 수도권 지역의 승하차데이터는 존재하지 않았다. 플젝 마감이 얼마 남지 않은터라.. 데이터를 구하고 다시 전처리를 할 시간이 충분하지 않았고, 우리는 서울지역만 일단 이용했다.
이부분 보완하고싶었는데... 교수님께서 받아주신 라이센스가 끝나벌임... 재학증명서 제출해야겠다.
다시 본론으로 돌아와서
지하철 승하차 데이터와 지하철 노선도 좌표를 .. 우리는 수기로 전처리를 진행했다.
1) 지하철 노선도 역 위치 좌표
https://data.seoul.go.kr/dataList/OA-21232/S/1/datasetView.do
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr
해당 데이터를 이용했으며, 이 데이터를 바로 뿌릴 수 없었따...
https://map.naver.com/v5/subway/1000/-/-/-?c=15,0,0,0,dh
네이버 지도
공간을 검색합니다. 생활을 연결합니다. 장소, 버스, 지하철, 도로 등 모든 공간의 정보를 하나의 검색으로 연결한 새로운 지도를 만나보세요.
map.naver.com
그래서 네이버지도에서 제공해주는 노선도 이미지를 다운받고, 해당 이미지를 사이즈에 맞춰서 태블로에 시각화 하였다. 그리고 하나하나 각 역별로 이미지 내의 좌표를 찍고 기록하여 엑셀 파일들을 만들었다.
정말 힘든 시간슨...

여기서 호선이 1호선, 2호선 이런식으로 모두 작성되어있던 것이 아니라 1호선의 경우에는 경부, 경인 등으로 쪼개져있었고, 일산선, 안산과천선 등 다양한 이름으로 세세하게 적혀있었다. 그래서 이 부분들도 우리에게 익숙한 호선으로 모두 바꿔주는 과정을 거쳤다.
2) 지하철 승하차 데이터
승하차 데이터의 일별 데이터는 날짜로만 이루어져있어 평일, 주말로 나눠보기 위해 파이썬을 이용해 합치고 전처리하는 과정을 거쳤다. 이때 코로나로 인해 막차 시간이 조정된 해는 24시 이후 열차가 1~2대밖에 없던 것으로 확인되어 23~24시에 포함시켰다.
getting_on_and_off_2019 = pd.read_csv('서울교통공사 2019년 일별 역별 시간대별 승하차인원(1_8호선).csv', encoding='cp949')
getting_on_and_off_2020 = pd.read_csv('서울교통공사 2020년 일별 역별 시간대별 승하차인원(1_8호선).csv', encoding='cp949')
getting_on_and_off_2021 = pd.read_csv('서울교통공사 2021년 일별 역별 시간대별 승하차인원(1_8호선).csv', encoding='cp949')
getting_on_and_off_2022 = pd.read_csv('서울교통공사_역별 일별 시간대별 승하차인원 정보_2022.csv', encoding='cp949')
# 2019를 기준으로 column명 모두 변경
columns = ['날짜', '호선', '역번호', '역명', '승하차여부', '~6', '6~7', '7~8',
'8~9', '9~10', '10~11', '11~12', '12~13', '13~14', '14~15', '15~16', '16~17',
'17~18', '18~19', '19~20', '20~21', '21~22', '22~23', '23~24', '24~']
columns_2021 = ['날짜', '호선', '역번호', '역명', '승하차여부', '~6', '6~7', '7~8',
'8~9', '9~10', '10~11', '11~12', '12~13', '13~14', '14~15', '15~16', '16~17',
'17~18', '18~19', '19~20', '20~21', '21~22', '22~23', '23~']
# 2019 데이터 전처리
getting_on_and_off_2019 = getting_on_and_off_2019.drop('(단위:명)', axis=1)
getting_on_and_off_2019 = getting_on_and_off_2019.drop(0, axis=0)
getting_on_and_off_2019.columns = columns
# 2020 데이터 전처리
getting_on_and_off_2020.columns = columns
# 2021 데이터 전처리
getting_on_and_off_2021 = getting_on_and_off_2021.drop(['연번', '합 계'], axis=1)
getting_on_and_off_2021.columns = columns_2021
# 2022 데이터 전처리
getting_on_and_off_2022 = getting_on_and_off_2022.drop('연번', axis=1)
getting_on_and_off_2022.columns = columns
getting_on_and_off_total = pd.concat([getting_on_and_off_2019, getting_on_and_off_2020,
getting_on_and_off_2021, getting_on_and_off_2022], ignore_index=True)
getting_on_and_off_total.to_excel('일별 역별 시간별 승하차 인원 종합.xlsx', index=False)1차적으로 전처리를 한 후, 엑셀파일로 저장된 것을 "하차데이터 평균+승차데이터평균"으로 계산하여 유동인구를 파악할 수 있도록 했다.
유동인구의 기준을 "하차데이터 평균 + 승차데이터 평균"으로 계산한 이유는 다음과 같다.
ⓛ 평일인 월~금의 하차데이터를 모두 더해 평균을 내고, 승차데이터의 월~금을 모두 더해 평균을 내 승차데이터의 평균과 하차데이터의 평균을 더해줌
② 주말일 토, 일의 하차 데이터를 모두 더해 평균을 내고, 승차데이터의 토, 일을 모두 더해 평균을 내어 각각을 더해줌
: 승차데이터와 하차데이터를 모두 더한 후 평균을 낸 경우... 뭔가 문제가 있었다. 근데 왜 기억이 안나지!?!?!??! 중복으로 계산이 되던가 뭔가 누락되던가 그래서 따로 계산하고 더했었는데... 마무리된지 한달 반이나 지나서 그런가 잘 기억나지 않는다.. 이런
이때 각 역사 플랫폼 내의 면적별 수용 가능 인원을 구해 더 구체적인 혼잡도를 제공할 수 있을 것이라고 생각된다.
여기서 혼잡도 데이터를 사용하지 않은 이유는 혼잡도 데이터는 열차 내의 혼잡도를 제공하기에 우리가 원하는 바와 달랐기 때문이다.
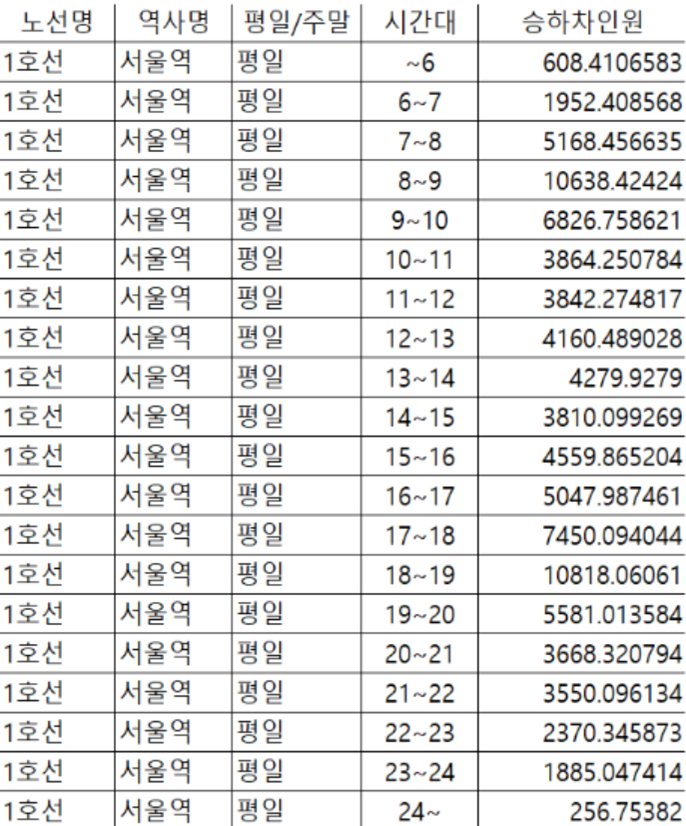
이때 시간대별 필터를 만들 수 있길 바랬는데 시간대가 행이 아닌 열에 위치하다보니 시간대별 필터가 만들어지지 않아 수기로 행렬변환 과정을 거쳤다.
(이때 피벗 이용했으면 참 쉬웠을텐데...왜 그생각을 못했을까..)
그리고 아우터 조인을 통해 이미지 상의 좌표가 담긴 시트와 시간대별 승하차데이터를 합쳐서 시각화하는 과정을 거쳤다.
4. 시각화 결과
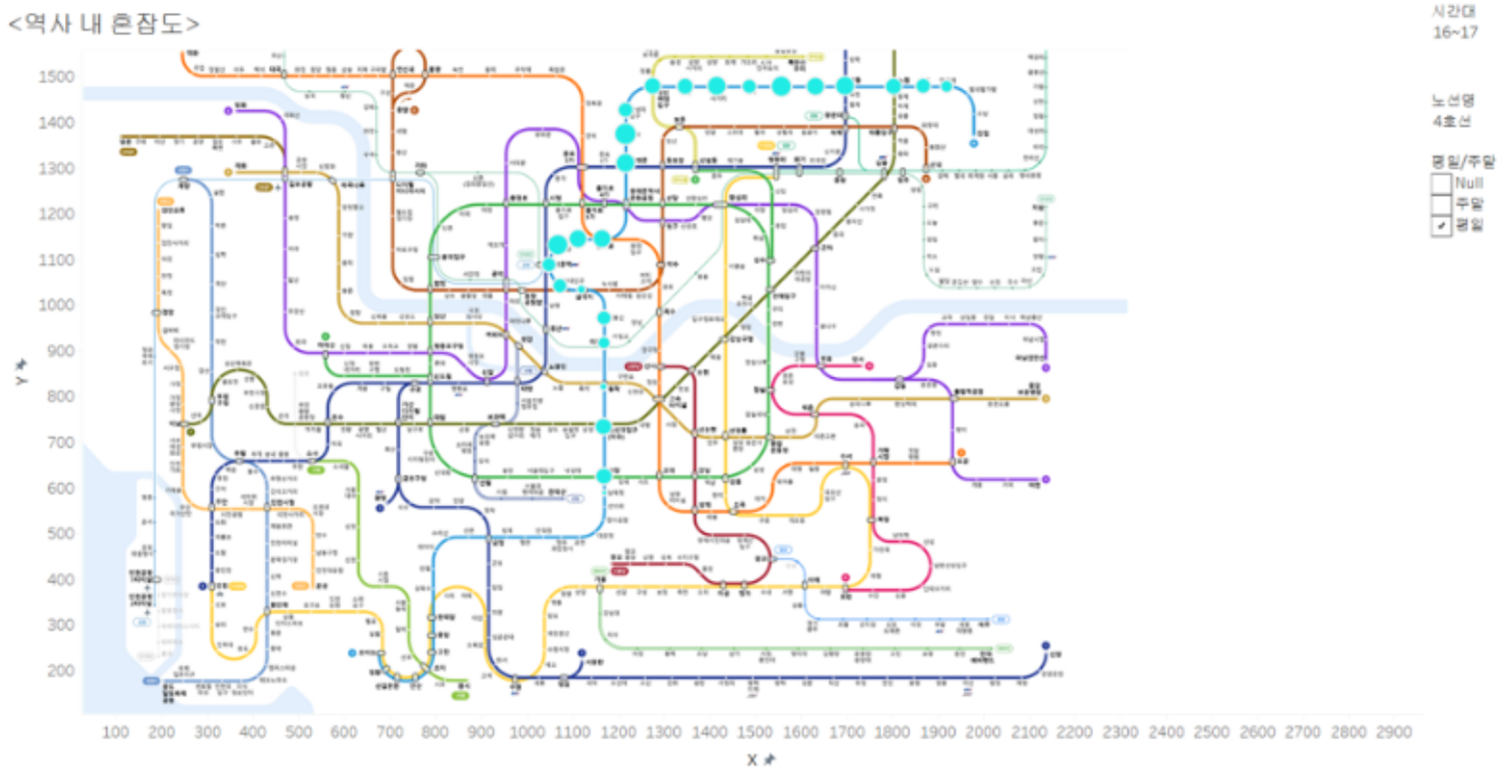
현재 태블로 파일을 열어볼 수 없어 움짤을 만들지 못해 참 아쉽지만..
이런식으로 구성이 되어있다.
원하는 시간대, 원하는 호선, 원하는 요일(평일/주말) 필터링을 통해 원하는 곳을 볼 수 있다.
해당 이미지는 16~17시의 평일 4호선이 시각화 되어있다.
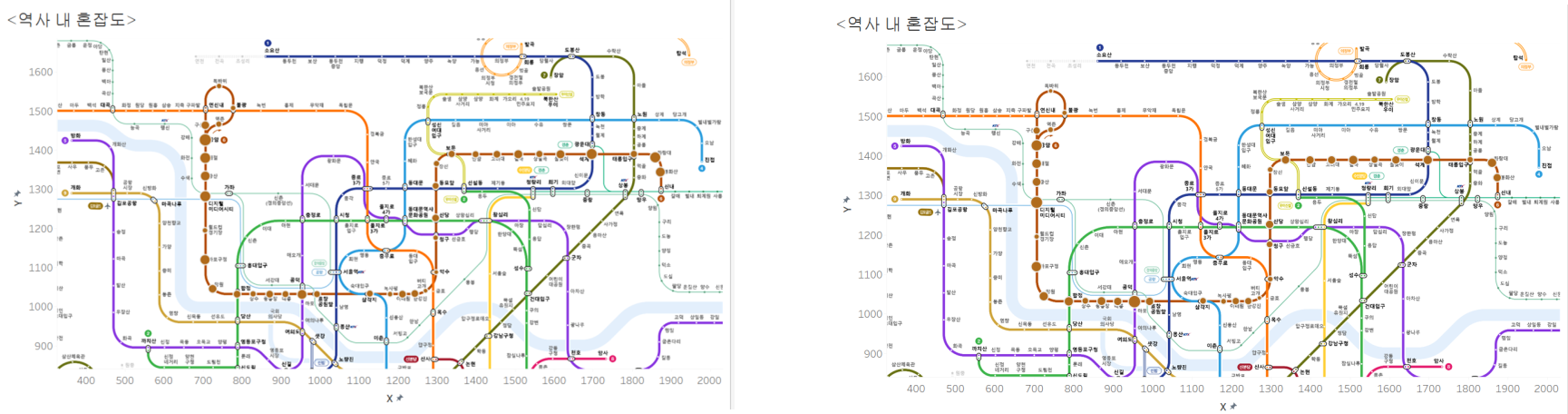
그리고 6호선의 6~7시, 8~9시를 비교해보면 확연히 원의 사이즈가 다른 구간이 있음을 알 수 있다.
특히 공덕, 석계의 경우 이른시간보다 대표적인 출근시간에 유동인구가 늘어나는 것을 확인할 수 있으며 이동거리가 멀어지는 디지털미디어시티에서 응암방향의 역들의 경우에는 이른시간에 유동인구가 더 많은 것을 알 수 있다.
5. 해결방안
이런 방식으로 열차 내의 혼잡도 뿐만 아니라 역사 플랫폼 및 환승구의 혼잡도 또한 제공된다면 안전문제와 인력 배치 문제를 해결하는데 도움이 될 것으로 판단된다.
이건 내 개인적인 목표인데, 어느정도 모델들에 대한 지식이 쌓이면 승하차 인원 예측을 해보고 싶다.
'2022 > 데이터시각화' 카테고리의 다른 글
| [데이터 시각화] 시각화 기본 5 (재정리) (0) | 2022.12.22 |
|---|---|
| [데이터 시각화] 시각화 기본 4 (재정리) (0) | 2022.12.22 |
| [데이터 시각화] 시각화 기본 3 (재정리) (0) | 2022.12.22 |
| [데이터 시각화] 시각화 기본 2 (재정리) (1) | 2022.12.22 |
| [데이터 시각화] 시각화 기본 1 (재정리) (0) | 2022.12.22 |