Classification Evaluation
2023. 8. 2. 21:51ㆍ개인활동/파이썬 머신러닝 완벽가이드
평가
- 모델을 돌렸다면 얼마나 이 모델이 정확한지 파악할 수 있어야 한다.
- 어떤 모델을 사용하냐에 따라 성능평가지표가 달라진다.
- 평가가 가능한 것은 정답이 있는 학습 방식이다.
- Quiz1
- 정답이 있는 학습방식에서만 평가가 가능한 이유는 무엇일까?
- 머신러닝에서 성능평가지표를 이용해 평가할 수 있는 것은 supervised learning (지도학습)이다.
- 딥러닝 모델들 중 label(정답)이 존재하는 모델이라면 마찬가지로 성능평가지표를 이용해 모델의 성능을 파악할 수 있다.
성능평가지표
- Classification 성능평가지표
- Regression 성능평가지표
1. Classification 성능 평가지표
1 ) Accuracy
2 ) Confusion Matrix
3 ) Precision, Recall
4 ) F1 Score
5 ) ROC, AUC Curve
1) Accuracy
- 실제데이터와 예측데이터가 얼마나 같은지를 알려주는 지표이다.
- Accuracy = 예측 값 중 실제 값과 일치한 데이터 건수 / 전체 데이터 건수
- 이 지표는 모델의 성능을 왜곡해 보여줄 수 있어 다른 지표들도 함께 봐야 한다.
- 특히 Binary Classification의 경우 모델의 성능을 왜곡시키기 쉽다.
- 아래는 Accuracy를 보기 위한 예시 코드이다.
import pandas as pd
from sklearn.datasets import load_breast_cancer # 분류해볼 데이터
from sklearn.linear_model import LogisticRegression # Classification 모델 중 하나
from sklearn.model_selection import train_test_split # 학습용 데이터와 테스트용 데이터를 분리해주는 메소드
from sklearn.metrics import accuracy_score # 정확도를 평가해주는 함수
data = load_breast_cancer()
X = data.data # load_breast_cancer()에서 제공하는 함수를 이용해 feature 추출
y = data.target # 우리가 맞춰야 할 target 추출
# train, test set으로 분리해주기
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)train_test_split()란?
- train set과 test set을 분리시켜주는 메소드
- 각 feature와 target을 파라미터로 넣어줌
- 몇대몇의 비율로 train set과 test set을 나눠주고 싶은지 test_size를 이용해 설정
- random_state가 설정되지 않은 경우 이 메소드를 불러올 때마다 다른 데이터들이 train set, test set에 들어가게 됨
- 이때 항상 같은 값이 train, test set에 들어가길 바랄 때 random_state를 설정해줌
- 이 숫자의 경우 본인이 원하는 숫자로 설정해도 괜찮음
- train, test set을 분리하는 다른 방법은?
- k-fold 교차 검증이라는 방식이 있음
- 이는 overfitting을 해결하는데 도움이 되는 학습 방식
- train, test set이 분리되어있을 때 train set 중 일부를 validation set으로 만들어주고 test set으로 검증하기 전 validation set으로 검증 해보는 과정을 거침
- 여기서 k-fold는 train set을 k등분 하여 1개의 셋은 validation set으로 이용하고 나머지는 train set으로 이용
- 그리고 이 과정을 k번 거치는 것을 의미함
<img src="https://img1.daumcdn.net/thumb/R1280x0/?fname=http://t1.daumcdn.net/brunch/service/user/ErZ/image/VrIxn4n25zQBuoF7uK4k8gP_WPk.png", witdh=600> - 이 외에도 stratified k-fold 등이 존재함
{kind=link}
# train, test set으로 나누어준 데이터를 모델에 넣어 학습
# Logistic Regression(로지스틱 회귀): 회귀라는 이름을 가지고 있으나 분류문제를 해결할 때 사용, 특히 binary classification
lr = LogisticRegression()
lr.fit(X_train, y_train) # train set을 넣어 학습시키기
y_pred = lr.predict(X_test)
# accuracy_score 메소드를 이용한 accuracy 확인해보기
acc = accuracy_score(y_test, y_pred)
acc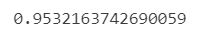
2) Confusion matrix
- 위에서 본 데이터는 위스콘신주의 유방암 데이터셋이다.
- 이 데이터셋은 binary Classification으로 걸렸는가, 걸리지 않았는가를 보여준다.
- 이런 binary class의 경우에는 target값이 불균형 한 경우 accuracy만 보는 것은 잘못된 결론을 도출할 수 있다.
- 이런 일을 막기 위해 확인해야하는 다른 지표들 중 하나는 바로 confusion matrix이다.
- 모델이 예측하는 과정에서 얼마나 헷갈리고 있는지를 파악할 수 있는 지표이다.
- 예측 오류가 어느정도인지, 어떤 유형의 예측 오류가 발생하였는지를 파악할 수 있다.
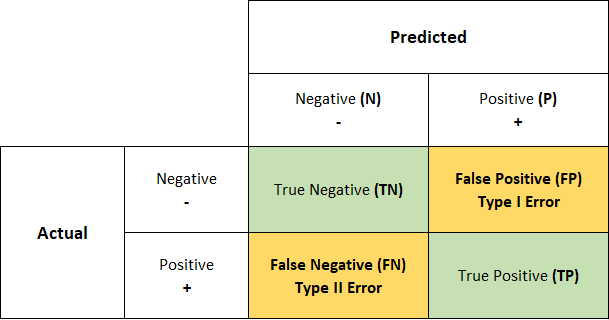
- True Negativ(TN): Negative 값인 0으로 예측했는데, 실제로도 Negative 값인 0인 경우 = Negative 값을 제대로 예측한 경우
- False Positive(FP): Positive 값인 1로 예측했는데, 실제로는 Negative 값인 0인 경우 = Negative 값을 제대로 예측하지 못한 경우
- False Negative(FN): Negative 값인 0으로 예측했는데, 실제로는 Psitive 값인 1인 경우 = Positive 값을 제대로 예측하지 못한 경우
- True Positive(TP): Positive 값인 1로 예측했는데, 실제로도 Positive 값인 1인 경우 = Positive 값을 제대로 예측한 경우
# 이 데이터에서는 양성종양인지, 악성종양인지 여부가 y(target=class)값에 존재함
# 0인 경우 malignant(악성종양), 1인 경우 benign(양성종양)
from sklearn.metrics import confusion_matrix
cf_mat = confusion_matrix(y_test, y_pred)
cf_mat
# value_counts의 경우에는 data frame 이나 series 데이터에서만 사용할 수 있음
pd.Series(y_test).value_counts()
- 위의 confusion matrix를 해석해보자.
- matrix는 행렬을 의미한다.

- 양성종양을 양성종양으로 파악한 데이터는 51개, 악성종양을 악성종양으로 예측한 것은 107개이다.
- 양성종양을 악성종양으로 예측한 것은 12개
- 악성종양을 양성종양으로 예측한 것은 1개
- 잘못 예측한 양성을 악성으로, 악성을 양성으로 중 더 위험한 경우는 무엇일까?
- FP를 1종오류, FN을 2종 오류라고 이야기함
- 1종 오류가 더 위험하기에 특히 제약, 의료분야에서는 1종 오류를 통제하려 노력함
3) Precision, Recall
- 위의 confusion matrix를 바탕으로 몇가지 비율을 보고자 한다.
- Precision은 정밀도로 Positive로 예측한 것 중 맞춘 것의 비율이라고 할 수 있다.
- Positive 예측 성능을 더욱 정밀하게 측정하기 위한 평가지표이며 양성 예측도라고도 한다.
- Precision = TP / (TP + FP)
- Recall은 재현율로 실제로 Positive인 것중 맞춘 것의 비율이라고 할 수 있다.
- 다른 말로 True Positive Rate(TPR), Sensitivity(민감도)
- Negative 값을 Positive라고 예측할 때 큰 문제가 생기는 분야에서 중요하게 다루는 지표이다.
- Precision과 분모의 값이 다르다.
- Recall = TP / (TP + FN)
- 두 지표가 모두 높을 수록 성능이 좋다고 해석할 수 있다. 근데 왜?
- 제대로 맞춘 것이 많을수록 Precision 값과 Recall값이 커지기 때문이다.
- 따라서 두 값이 클수록 모델의 성능이 좋다고 판단할 수 있는 것이다.
- 그러나 이 둘은 trade-off 관계를 가지고 있다.
- 한쪽이 커지면 한쪽은 작아지는 관계이다.
- 이런 이유로 두 지표의 값을 모두 키우는데 어려움이 많다.
- 모델이 예측하는 방식: binary classification 기준
- 어느 한쪽을 예측할 때 기준값을 두고 기준 이상으로 예측하였다면 P, 기준 이하로 예측하였다면 N으로 예측한다.
- predict_proba()라는 메소드를 이용해 예측한 각 값들이 어느정도의 확률로 예측되었는지 확인할 수 있다.
- 이때 기준값을 조절하여 precision과 recall을 조절할 수 있다.
from sklearn.metrics import precision_score, recall_score
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print(precision, recall)
# 두 값이 모두 크게 나왔다는 것은 잘못 예측한 값이 충분히 작았기 때문에 가능한 것
# 굉장히 잘 예측하였음을 파악할 수 있음

4) F1 Score
- Precision과 Recall을 이용한 평가지표로 데이터의 클래스가 불균형할 때 평가지표로 사용하면 좋다.
- F1_score = 2 * ( Precision * Recall / Precision + Recall)
- Precision과 Recall의 값이 어느 한쪽으로 치우치지 않았을 때 큰 값을 보임
from sklearn.metrics import f1_score
f1 = f1_score(y_test, y_pred)
f1
5) ROC Curve, AUC
- ROC(Receiver Operation Characteristic) Curve
- 과거 통신장비 성능 평가를 위해 고안된 수치로 현재는 의학분야에서 많이 사용된다.
- X축은 False Positive Rate(FPR), Y축은 True Positive Rate(TPR, 재현율, 민감도)으로 잡혀있다.
- TPR에 대응하는 지표로 True Negative Rate(TNR, 특이성, Specifity)이 있다.
- 실제로 Negative인 것 중 Negative가 얼마나 정확히 예측되었는가를 보여준다.
- TNR = TN / (FP + TN)
- FPR의 변화에 따라 TPR이 어떻게 변하는지를 보여준다.
- AUC(Area Under Curve)
- ROC Curve의 밑 면적을 구한 것으로 1에 가까울수록 좋은 수치이다.
- AUC가 커지기 위해서는 FPR이 작은 상태에서 TPR이 얼마나 커질 수 있는지가 관건이다.
from sklearn.metrics import roc_curve, roc_auc_score
import matplotlib.pyplot as plt
import numpy as np
def roc_curve_plot(y_test, pred_proba):
# 임계값(Thresholds)에 따른 FPR, TPR 값을 반환받음
fprs, tprs, thresholds = roc_curve(y_test, pred_proba)
# ROC Curve 그리기
plt.plot(fprs, tprs, label='ROC')
# 가운데 기준이 되는 직선을 그려줌: binary에서 최소한 50:50의 확률로 찍어서 맞출 수 있음
plt.plot([0, 1], [0, 1], 'k--', label='Random')
start, end = plt.xlim()
# x축의 scale을 0.1 단위로 설정
plt.xticks(np.round(np.arange(start, end, 0.1), 2))
# X, Y축의 범위 0~1로 설정
plt.xlim(0, 1)
plt.ylim(0, 1)
# 각 축에 이름을 붙여줌
plt.xlabel('FPR(1 - Sensitivity)')
plt.ylabel('TPR(Recall)')
plt.legend()
plt.show()
# 첫번째 열은 0으로 분류할 확률, 두번째 열은 1로 분류할 확률
pred_proba = lr.predict_proba(X_test)
pred_proba
# 두번째 열만 추출 만들어줌
# 1로 분류할 확률만 추출
pred_proba = lr.predict_proba(X_test)[:, 1]
roc_curve_plot(y_test, pred_proba)
# AUC 값도 확인해보자
from sklearn.metrics import roc_auc_score
roc_score = roc_auc_score(y_test, pred_proba)
roc_score- ROC Curve의 밑 면적의 거의 대부분이 나온 것을 확인할 수 있게된다.
'개인활동 > 파이썬 머신러닝 완벽가이드' 카테고리의 다른 글
| Regression Evaluation (0) | 2023.08.03 |
|---|---|
| 앙상블 분류 모델 (0) | 2023.05.01 |